前言
今天整理电脑资料,无意间翻出来一道CTF题。考题内容是变种base64加解密,解题程序是当时做题是从互联网收集,个博客做个记录,顺便回顾下base64加解密原理。
base64加解密原理
- base64字符的组成部分
A-Z、a-z、0-9、+、/
26 + 26 + 10 + 2 = 64 - Base64表
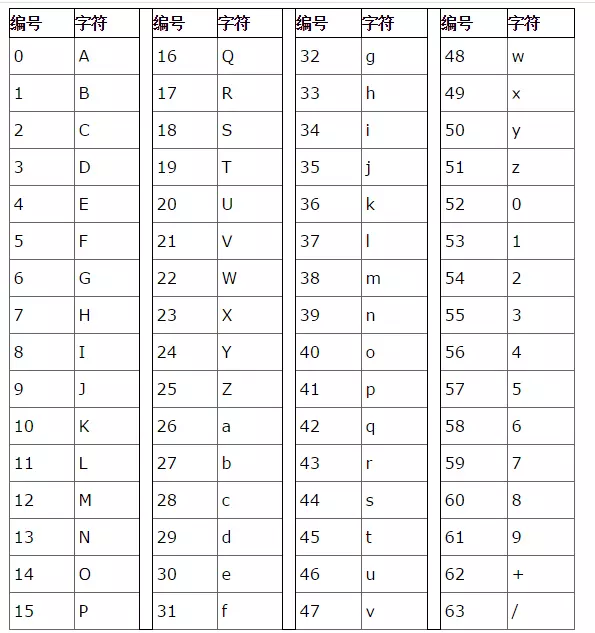
- 加密原理 先将每三个字符分离,最后有可能剩0个或者1个或者2个字符。
- 整三个:将三个字符转换为ascii二进制码,得到24bit(3*8bit),然后再按顺序分为4份(每6bit为一份)。最后,将这四份二进制转换为4份十进制,再按照Base64字符表转为4个字符。
- 分离后剩1个字符:将这一个字符转换为ascii二进制码,先切一个6bit还剩2bit,再将这2bit后面补4个0。最后,将这两份二进制转换为2份十进制,再按照Base64字符表转为2个字符,后面再补两个等于号(这里两个等号打不出来)。
- 分离后剩2个字符:将这一个字符转换为ascii二进制码,先切两个6bit还剩4bit,再将这2bit后面补2个0。最后,将这三份二进制转换为3份十进制,再按照Base64字符表转为3个字符,后面再补一个等于号(=)。
- Base64对于中文的不同编码可能会出现不同的结果,具体要看中文用的是什么编码。
- 以字符串"php"为例
对应ASCII: 01110000 01101000 01110000
每6位分割: 011100 000110 100001 110000
对应10进制值: 28 6 33 48
Base64对应的字符:c G h w
结果: php = cGhw(base64) - 解密 看懂加密,解密就是加密的逆向,这里要强调的是:Base64解密也是靠着Base64表解密的,如果碰到不在Base64表的字符(空格,<,>,等等),将会跳过这些字符,仅将在表内的字符组成一个新的字符串进行解码。
base64变种
base64变种主要是围绕base64码表,比如对码表做凯撒加密处理,或是题目给一段自定义64码表
base64加解密程序
# python版本
# coding:utf-8
#s = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
s = "uL9BG2i1po7z6MnCQf8rvDxJt5Ahw3kjlKWPesqy+EdZbc/aS0HOVXYmNgIRTFU4"
def My_base64_encode(inputs):
# 将字符串转化为2进制
bin_str = []
for i in inputs:
x = str(bin(ord(i))).replace('0b', '')
bin_str.append('{:0>8}'.format(x))
#print(bin_str)
# 输出的字符串
outputs = ""
# 不够三倍数,需补齐的次数
nums = 0
while bin_str:
#每次取三个字符的二进制
temp_list = bin_str[:3]
if(len(temp_list) != 3):
nums = 3 - len(temp_list)
while len(temp_list) < 3:
temp_list += ['0' * 8]
temp_str = "".join(temp_list)
#print(temp_str)
# 将三个8字节的二进制转换为4个十进制
temp_str_list = []
for i in range(0,4):
temp_str_list.append(int(temp_str[i*6:(i+1)*6],2))
#print(temp_str_list)
if nums:
temp_str_list = temp_str_list[0:4 - nums]
for i in temp_str_list:
outputs += s[i]
bin_str = bin_str[3:]
outputs += nums * '='
print("Encrypted String:\n%s "%outputs)
def My_base64_decode(inputs):
# 将字符串转化为2进制
bin_str = []
for i in inputs:
if i != '=':
x = str(bin(s.index(i))).replace('0b', '')
bin_str.append('{:0>6}'.format(x))
#print(bin_str)
# 输出的字符串
outputs = ""
nums = inputs.count('=')
while bin_str:
temp_list = bin_str[:4]
temp_str = "".join(temp_list)
#print(temp_str)
# 补足8位字节
if(len(temp_str) % 8 != 0):
temp_str = temp_str[0:-1 * nums * 2]
# 将四个6字节的二进制转换为三个字符
for i in range(0,int(len(temp_str) / 8)):
outputs += chr(int(temp_str[i*8:(i+1)*8],2))
bin_str = bin_str[4:]
print("Decrypted String:\n%s "%outputs)
print()
print(" *************************************")
print(" * (1)encode (2)decode *")
print(" *************************************")
print()
num = input("Please select the operation you want to perform:\n")
if(num == "1"):
input_str = input("Please enter a string that needs to be encrypted: \n")
My_base64_encode(input_str)
else:
input_str = input("Please enter a string that needs to be decrypted: \n")
My_base64_decode(input_str)
/*C语言版本*/
#include <stdio.h>
#include <string.h>
// 全局常量定义
// const char * base64char = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
const char * base64char = "uL9BG2i1po7z6MnCQf8rvDxJt5Ahw3kjlKWPesqy+EdZbc/aS0HOVXYmNgIRTFU4";
const char padding_char = '=';
/*编码代码
* const unsigned char * sourcedata, 源数组
* char * base64 ,码字保存
*/
int base64_encode(const unsigned char * sourcedata, char * base64)
{
int i = 0, j = 0;
unsigned char trans_index = 0; // 索引是8位,但是高两位都为0
const int datalength = strlen((const char*)sourcedata);
for (; i < datalength; i += 3){
// 每三个一组,进行编码
// 要编码的数字的第一个
trans_index = ((sourcedata[i] >> 2) & 0x3f);
base64[j++] = base64char[(int)trans_index];
// 第二个
trans_index = ((sourcedata[i] << 4) & 0x30);
if (i + 1 < datalength){
trans_index |= ((sourcedata[i + 1] >> 4) & 0x0f);
base64[j++] = base64char[(int)trans_index];
}
else{
base64[j++] = base64char[(int)trans_index];
base64[j++] = padding_char;
base64[j++] = padding_char;
break; // 超出总长度,可以直接break
}
// 第三个
trans_index = ((sourcedata[i + 1] << 2) & 0x3c);
if (i + 2 < datalength){ // 有的话需要编码2个
trans_index |= ((sourcedata[i + 2] >> 6) & 0x03);
base64[j++] = base64char[(int)trans_index];
trans_index = sourcedata[i + 2] & 0x3f;
base64[j++] = base64char[(int)trans_index];
}
else{
base64[j++] = base64char[(int)trans_index];
base64[j++] = padding_char;
break;
}
}
base64[j] = '\0';
return 0;
}
/** 在字符串中查询特定字符位置索引
* const char *str ,字符串
* char c,要查找的字符
*/
int num_strchr(const char *str, char c) //
{
const char *pindex = strchr(str, c);
if (NULL == pindex){
return -1;
}
return pindex - str;
}
/* 解码
* const char * base64 码字
* unsigned char * dedata, 解码恢复的数据
*/
int base64_decode(const char * base64, unsigned char * dedata)
{
int i = 0, j = 0;
int trans[4] = { 0, 0, 0, 0 };
for (; base64[i] != '\0'; i += 4){
// 每四个一组,译码成三个字符
trans[0] = num_strchr(base64char, base64[i]);
trans[1] = num_strchr(base64char, base64[i + 1]);
// 1/3
dedata[j++] = ((trans[0] << 2) & 0xfc) | ((trans[1] >> 4) & 0x03);
if (base64[i + 2] == '='){
continue;
}
else{
trans[2] = num_strchr(base64char, base64[i + 2]);
}
// 2/3
dedata[j++] = ((trans[1] << 4) & 0xf0) | ((trans[2] >> 2) & 0x0f);
if (base64[i + 3] == '='){
continue;
}
else{
trans[3] = num_strchr(base64char, base64[i + 3]);
}
// 3/3
dedata[j++] = ((trans[2] << 6) & 0xc0) | (trans[3] & 0x3f);
}
dedata[j] = '\0';
return 0;
}
// 测试
int main()
{
const unsigned char str[] = "a45rbcd";
const unsigned char *sourcedata = str;
char base64[512];
base64_encode(str, base64);
printf("编码:%s\n", base64);
char dedata[128];
base64_decode(base64, (unsigned char*)dedata);
printf("译码:%s", dedata);
getchar();
return 0;
}