
前言
最近openclaw风生水起,各大厂商推出了专属的“龙虾服务”。云主机服务商提供“龙虾”专用免费云主机;互联网大厂发布自家“龙虾”客户端并免费送token。但免费只是引流,等客户使用习惯后收费项目就会逐步展开。比如云主机仅限免费30天,免费token额度越送越少。所以要随心所欲长期折腾AI,还得是本地自建一套大模型,一次性投入解决token焦虑。在此记录分享我最近从零开始本地搭建大模型过程及趟过的坑。
正文
显卡选择
首次本地搭建大模型,所以目标比较低:
- openclaw能有不错畅快聊天体验(尝试过纯CPU跑模型,5分钟回一个消息完全没有客户体验)
- 简单信息查询,资料整理
基于以上需求,我计划投入400RMB尝试下本地搭建大模型。在海鲜市场逛了一圈后看中了Nvidia的Tesla系列M60显卡16G显存,300元左右(但在安装ollama就有点后悔了)
基础设置
- 主机电源500w以上
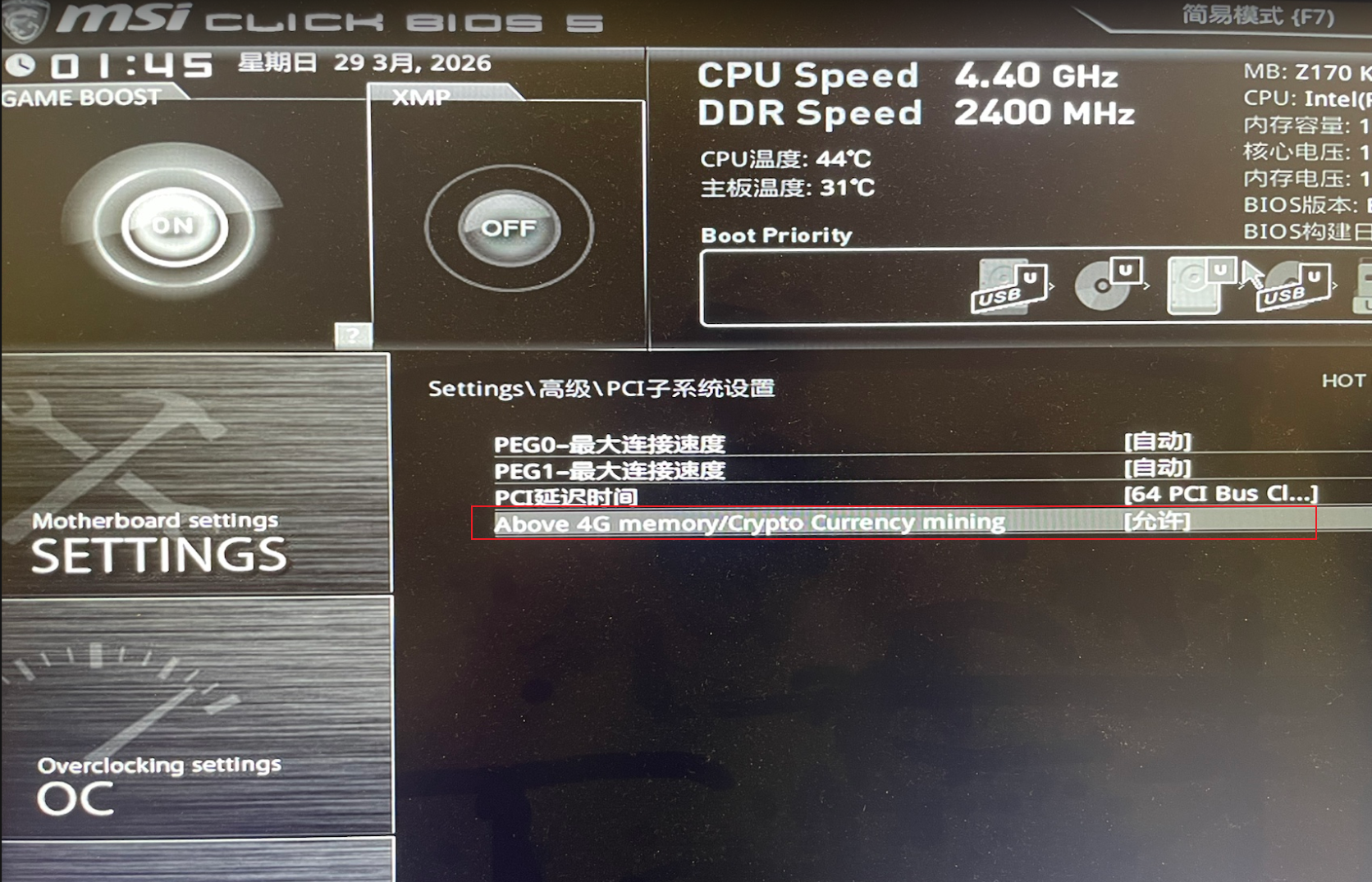
- 主板Bios中有Above 4G选项并开启。(我的微星Z170,bios里找了半天没找到,后面更新Bios固件后找到该选项)
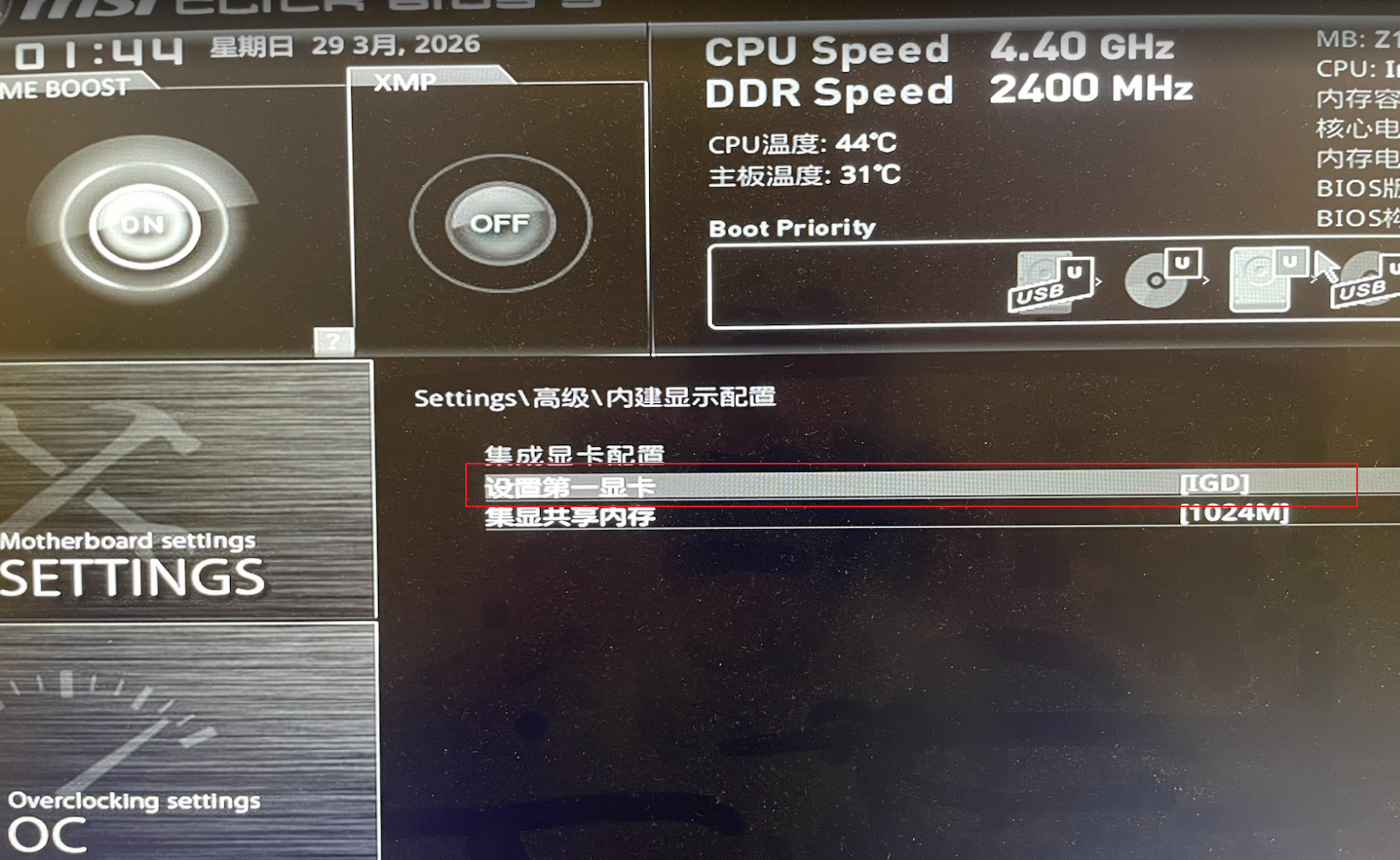
- 设置主板Bios,默认使用集显或亮机卡进操作系统(这坑上我趟了3天,如果没设置正常开机会黑屏或花屏)
- tesla显卡专用8Pin电源线,与主机电源8Pin线不通用需单独购买转接线。
驱动及CUDA安装
基本都按网上教程一步步操作,需要注意驱动和CUDA版本不能随意装,有绑定关系。可以先安装驱动,然后通过命令nvidia-smi -L 查看驱动支持最高的CUDA版本,再去下载安装CUDA
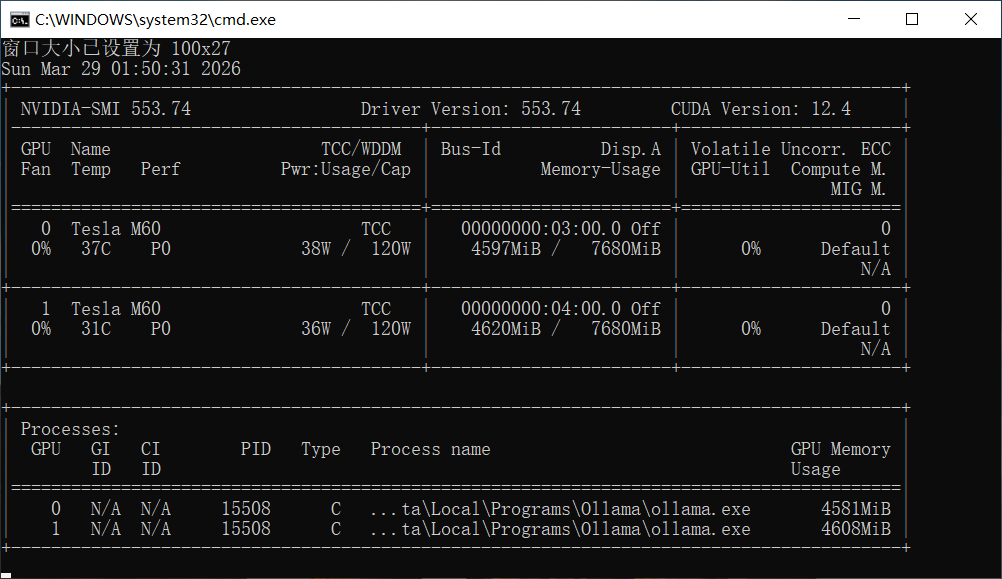
显卡调试
nvidia-smi -l 2
ollama安装配置
安装ollama在方法教程里面看到了这个表格,就知道显卡性能,再参考咸鱼价格就更好的选择。
| Compute Capability | Family | Cards |
|---|---|---|
| 9.0 | NVIDIA | H100 |
| 8.9 | GeForce RTX 40xx | RTX 4090, RTX 4080, RTX 4070 Ti, RTX 4060 Ti |
| NVIDIA Professional | L4, L40, RTX 6000 | |
| 8.6 | GeForce RTX 30xx | RTX 3090 Ti, RTX 3090, RTX 3080 Ti, RTX 3080, RTX 3070 Ti, RTX 3070, RTX 3060 Ti, RTX 3060 |
| NVIDIA Professional | A40, RTX A6000, RTX A5000, RTX A4000, RTX A3000, RTX A2000 | |
| 8.0 | NVIDIA | A10, A16, A2 |
| 7.5 | GeForce GTX/RTX | GTX 1650 Ti, TITAN RTX, RTX 2080 Ti, RTX 2080, RTX 2070, RTX 2060 |
| NVIDIA Professional | T4, RTX 5000, RTX 4000, RTX 3000, T2000, T1200, T1000, T600, T500 | |
| Quadro | RTX 8000, RTX 6000, RTX 5000, RTX 4000 | |
| 7.0 | NVIDIA | TITAN V, V100, Quadro GV100 |
| 6.1 | NVIDIA TITAN | TITAN Xp, TITAN X |
| GeForce GTX | GTX 1080 Ti, GTX 1080, GTX 1070 Ti, GTX 1070, GTX 1060, GTX 1050 | |
| Quadro | P6000, P5200, P4200, P3200, P5000, P4000, P3000, P2200, P2000, P1000, P620, P600, P500, P520 | |
| NVIDIA Tesla | P40, P4 | |
| 6.0 | NVIDIA Quadro | GP100 |
| 5.2 | GeForce GTX | GTX TITAN X, GTX 980 Ti, GTX 980, GTX 970, GTX 960, GTX 950 |
| Quadro | M6000 24GB, M6000, M5000, M5500, M, M4000, M2200, M2000, M620 | |
| NVIDIA Tesla | M60, M40 | |
| 5.0 | GeForce GTX | GTX 750 Ti, GTX 750, NVS 810 |
| Quadro | K2200, K1200, K620, M1200, M520, M5000, M, M4000, M, M3000, M, M2000, M, M1000, M, K620, M600, M500, M |
nvidia-smi -L # 展示可用显卡
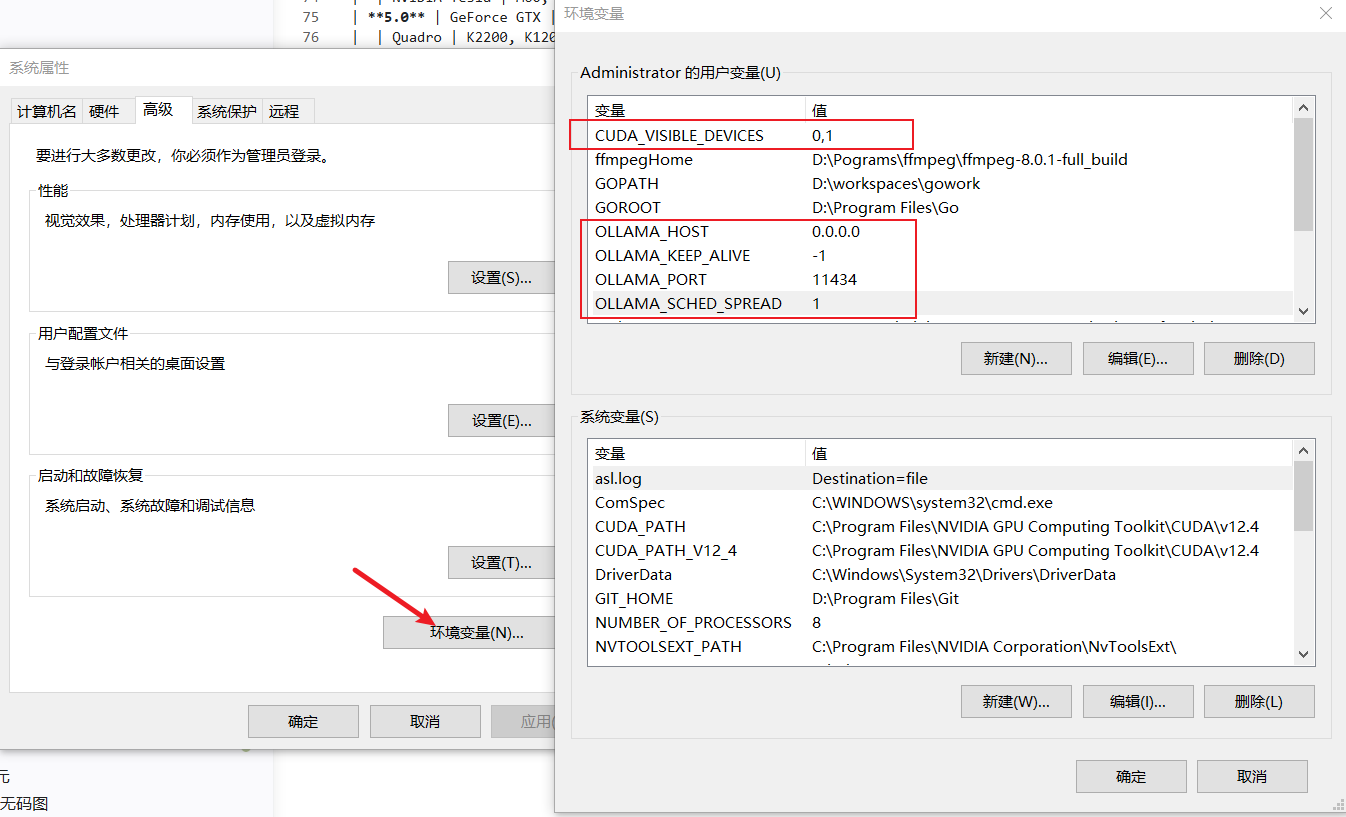
#修改ollama默认启动配置
CUDA_VISIBLE_DEVICES=0,1 #代表让ollama能识别到第几张显卡
OLLAMA_SCHED_SPREAD=1 #这几张卡均衡使用
OLLAMA_KEEP_ALIVE=-1 #模型一直加载, 不自动卸载
OLLAMA_HOST=0.0.0.0 #监听地址
OLLAMA_PORT=11434 #监听端口
openclaw本地配置
总结
记录分享我从选择显卡、BIOS设置、驱动安装到ollama配置过程中的坑,有需要的可以参考。
参考
Tesla V100 在 Windows 下安装配置
Nvidia Tesla P100在WIN10下目前(2026年1月28号)能启用WDDM和CUDA的最新版本
ollama部署deepseek, 多显卡负载均衡
保姆级教程 Ollama 部署 DeepSeek-R1 本地模型